安装完Java和Scala后,接下来就要进行Hadoop与Spark系统的搭建了。
但是重要的问题出现了,各环境之间的兼容性需要仔细考虑一下,不然可能会引起后续很多问题。本次学习参考的教程Hadoop的最新版本还是2.7.1,这个时候就很可怕了——之前计划安装的spark系统版本为3.x.y,并且基本打算安装最新的3.2.1。通过解压官网预构建Hadoop环境的Spark安装包发现,里面集成的Hadoop版本应该是3.3.1。
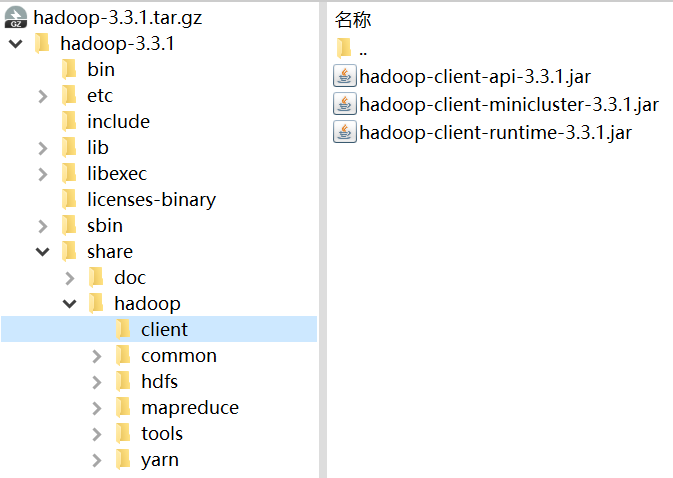
这是Hadoop 3.3.1安装包内截图,为什么放这张图?因为我想吐槽下下面那一张。
查阅学习的参考资料发现,教程所用环境基本较老,包括Spark版本也是2.x.y版本的。(众所周知,2.x.y与3.x.y基本是两种东西。)于是除了Hadoop版本之外,其他的一些组件,包括HBase,Hive等等,都得自己重新找互相兼容的版本了。
可这不是还没安装吗,怎么看是否兼容呢?
我不到啊。那么还能怎么办呢,继续看Spark安装包吧:
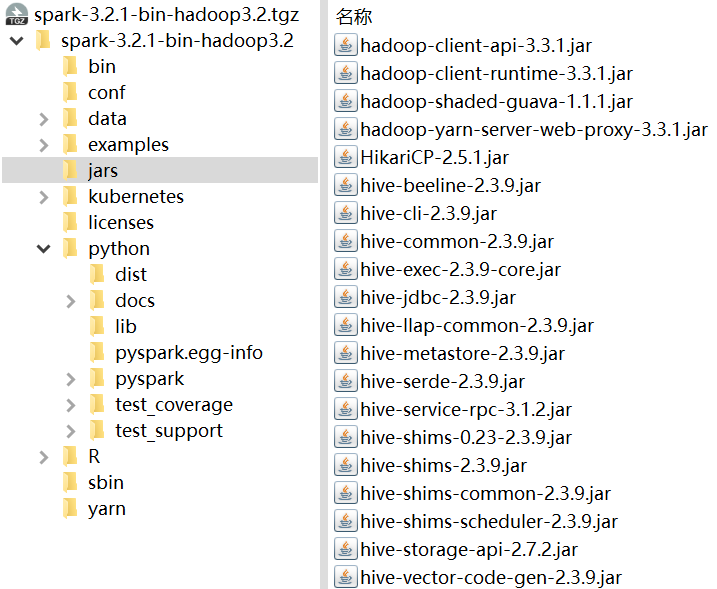
Spark-3.2.1-bin-with-hadoop-3.2安装包内截图(对照上图看看,怎么好意思说自己是3.2的,里面明明是3.3.1)
于是让人很难绷得住的事情发生了:这里集成的Hive版本怎么是2.3.9啊。为什么这么说?因为Hive是3.x.y对应Hadoop的3.x.y的。不信吗?看看人家的发行说明:


看到这里,我忽然开始怀疑自己了:Spark安装包那张图上说的2.3.9,就一定是2.3.9了吗?可能这个2.3.9并不是说的Hive版本呢?
于是我分别去Hive官网下载了2.3.9和3.1.2(理论上对应Hadoop 3.x.y版本的版本),打开安装包,发现现实总是残酷的:
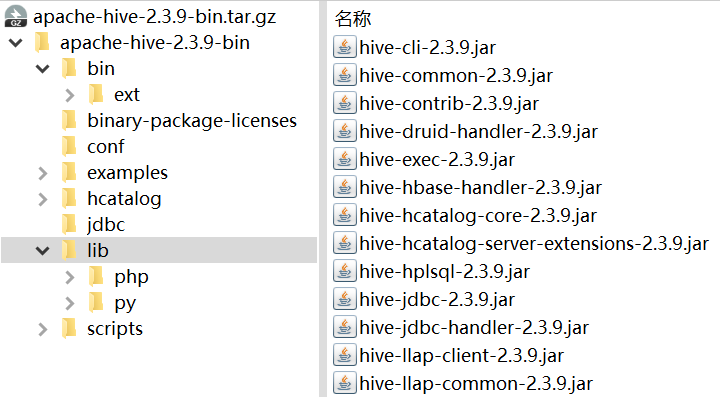

行了,Spark安装包里集成的环境就是Hive 2.3.9了。
那HBase呢?
到HBase的官方文档处找了半天,还是没找到和Hadoop版本对应的部分,然后我想起了有个东西叫网页查找。于是找到了这样一段话:
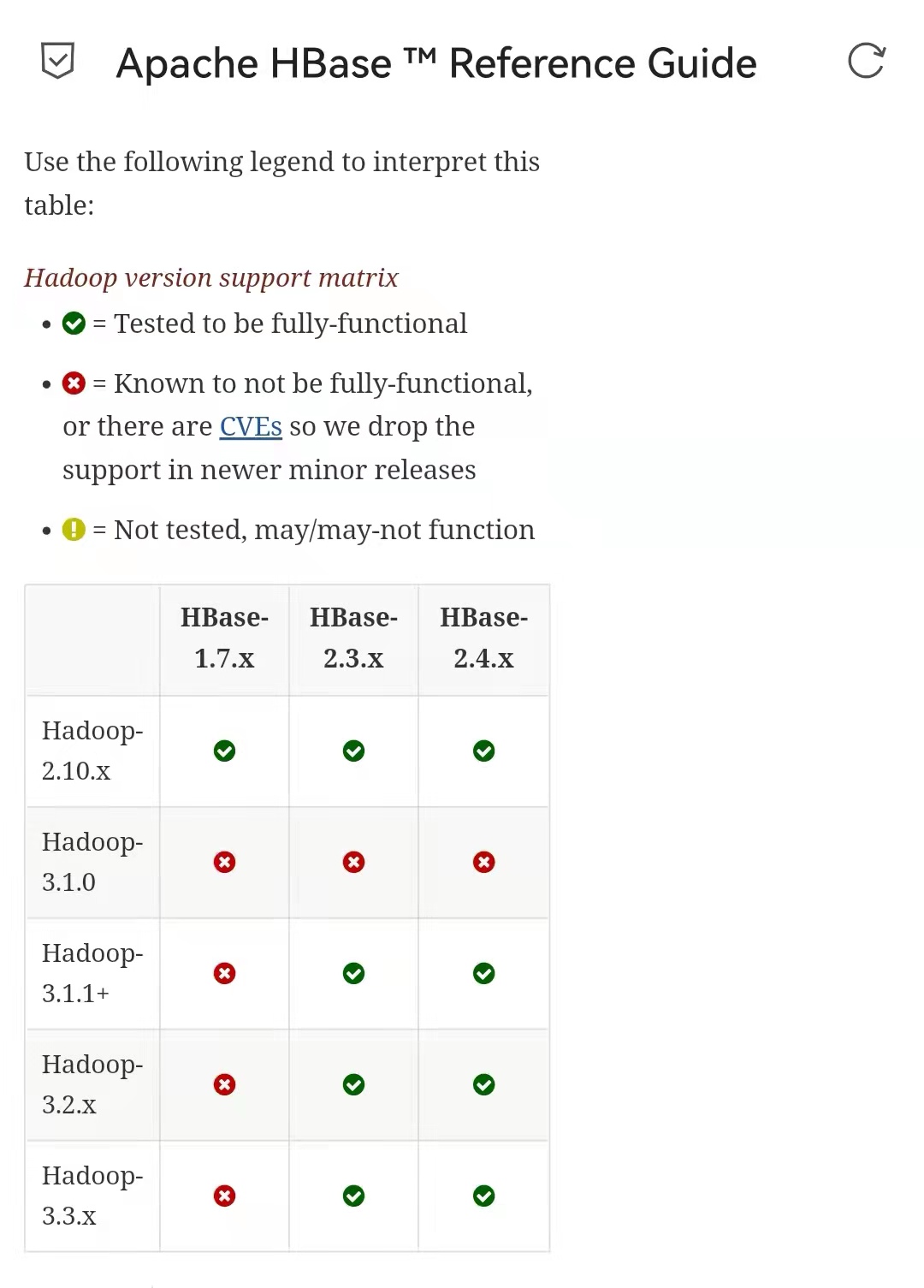
谢谢你,HBase!还有网页查找功能!
然后是HBase和Java的兼容性,忘了截图了,但Jdk8和11对于新一点的版本在兼容性上是基本没有问题的,太好了,不然从一开始的工作全部要……
HBase还提了一下Zookeeper的版本要求,很简单:越新越好,至少3.4.x。看了Spark安装包(集成了环境的那个)里的是3.6.2。
那么本次学习的各软件版本基本可以确定为以下几个了:(如果这次没分析对,之后出了问题再说吧)
| 软件 | 版本 |
|---|---|
| Spark | 3.2.1 |
| Hadoop | 3.3.1(虽然槽点很多) |
| Hive | 2.3.9(槽点依旧很多) |
| HBase | 2.4.10(先用着看一看) |
| Scala | 2.12.15(上文提过了) |
| Zookeeper | 3.6.2(暂定,反正HBase说越新越好) |